The SOR3D dataset consists of over 20k instances of human-object interactions. The capturing process involved three synchronized Microsoft Kinect v2 sensors (three capturing views) under controlled environmental conditions. The available data contain 1) RGB videos (1920×1080 pixels ), 2) depth map sequences (512×424 pixels). and c) 3D optical flow fields.
SOR3D Video Description
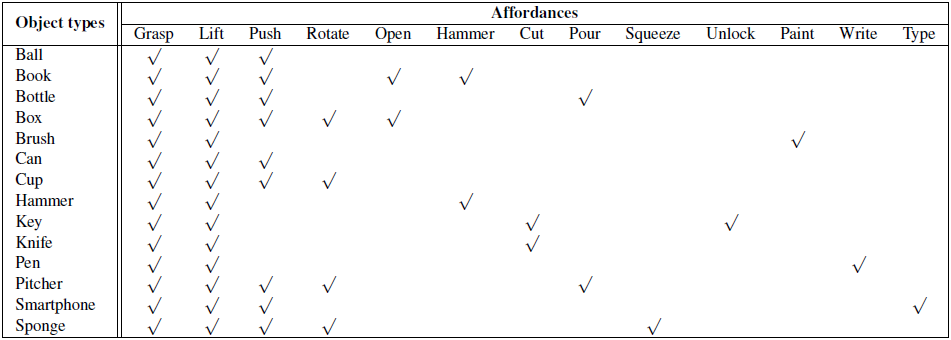
Data
The capturings from the 105 unique subjects (some of them were captured more than once) are split into train, validation and test sets (approximately 25%, 25% and 50%), according to the following table. All data are compressed to a custom “.scnz” format.
| Set | Subjects | Sessions | Size (compressed) in GB |
|---|---|---|---|
| train | 98 | 5255 | 414 |
| validation | 82 | 4428 | 325.3 |
| test | 197 | 10340 | 823 |
Pre-processing Pipeline (optional)
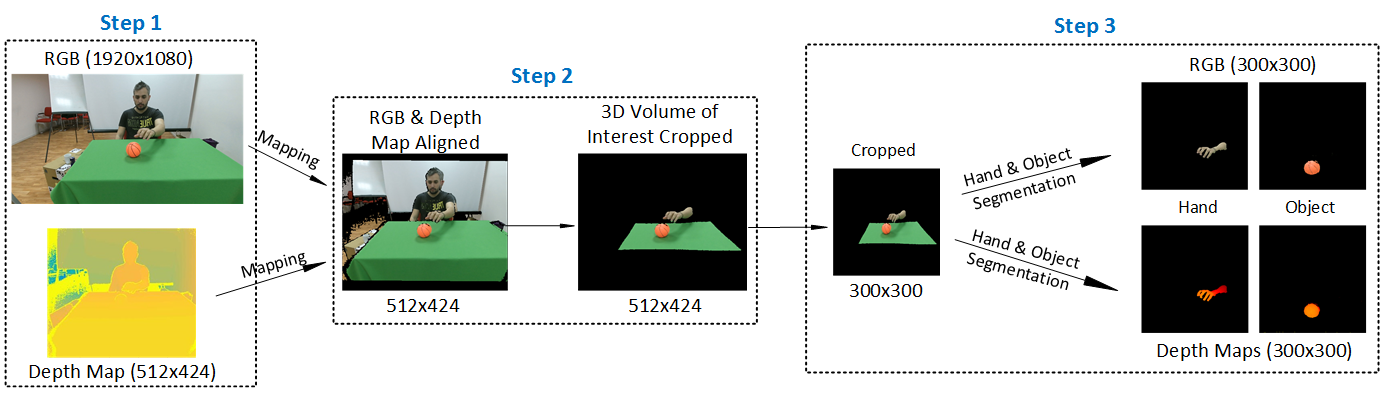
The figure above depicts the data pipeline, from data decompression (.scnz to .png) to hand and object segmentation.
Step 1 (required). The data from all RGB-D sensors are stored in a custom file format (.scnz), which uses lossless compression for depth and JPEG compression for RGB. This GUI (Windows) is used for decompression.
Step 2 (optional). Run the provided script (Matlab) for RGB and depth data alignment, and for cropping the 3D volume of interest.
Step 3 (optional). Use these scripts (github repo) for hand and object segmentation for both RGB and depth data.
The first step is mandatory in order to get the original data (.png). Steps 2 and 3 are optional as any available software for RGB and depth data alignment, cropping and segmenting data can be used.
The code used for the 3D optical flow computation is here (M. Jaimez et al., “A Primal-Dual Framework for Real-Time Dense RGB-D Scene Flow”, ICRA 2015).
Processed Data
Skip the pre-processing step and download the processed SOR3D data (SOR3D_processed_data):
- Colorized object-only depthmaps.
- Colorized hand-only depthmaps.
- Colorized hand-only 3D flow.
- Colorized hand-only 3D flow magnitude.
- Colorized hand-only 3D flow (accumulated)*.
- Colorized hand-only 3D flow magnitude (accumulated)*.
*all frames’ 3D flow is accumulated into 1 frame that has the footprint of the hand movement.
Usage for Academic Research
SOR3D is released only for academic research. Any researcher from an educational institute is allowed to use freely for academic purposes only. Redistribution and modification in any way or form are considered illegal. Images in this database are only allowed for demonstration in academic publications and presentations subjected to the Terms and Conditions defined below.
Terms and Conditions of Use
The use of SOR3D is governed by the following terms and conditions:
- Without the expressed permission of VCL, any of the following will be considered illegal: redistribution, modification and commercial usage of the dataset in any way or form, either partially or in its entirety.
- For the sake of privacy, images of all subjects in the dataset are only allowed for demonstration in academic publications and presentations.
- All users of the dataset agree to indemnify, defend and hold harmless, VCL and its officers, employees and agents, individually and collectively, from any and all losses, expenses and damages.
Related Publications
All publications using SOR3D or any parts of it should cite the following publication (pdf, arxiv):
- S. Thermos, G. T. Papadopoulos, P. Daras and G. Potamianos, “Deep Affordance-grounded Sensorimotor Object Recognition”, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6167-6175, Honolulu, Hawaii, USA, 2017.
By completing and submitting the online form below, you accept all above information, usage restrictions, terms & conditions of use and agree to include the above acknowledgement in any of your publications that will be using the SOR3D or any parts of it.
Acknowledgement
This work has received funding from the EU Horizon 2020 Framework Programme under grant agreement no. 687772 (MATHISIS project).