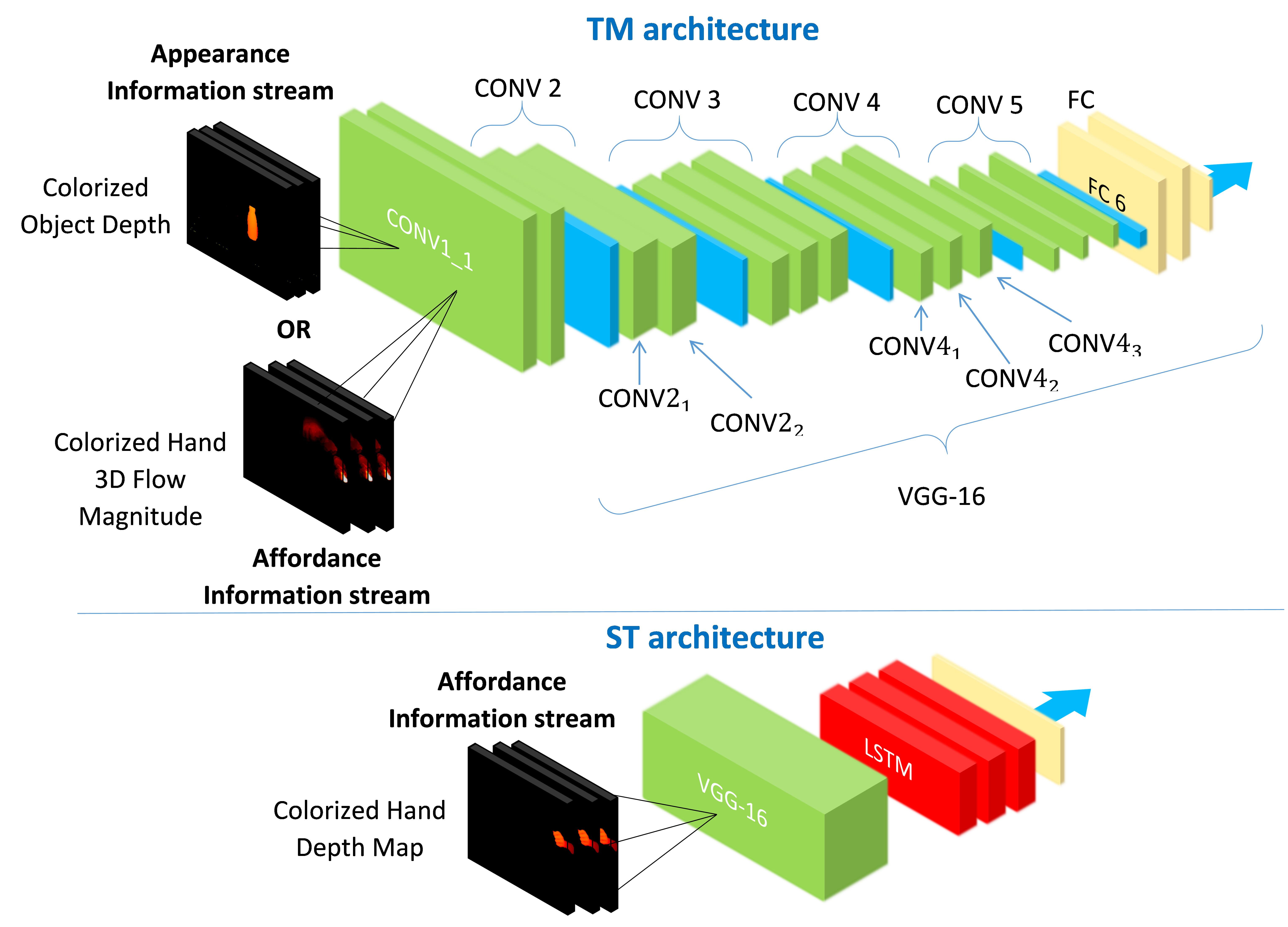
Figure 1. Single-stream models. Top: appearance CNN for object recognition, and affordance CNN (TM architecture). Bottom: affordance CNN-LSTM (ST architecture). The CNN layer notation used in this paper is depicted at the top figure.
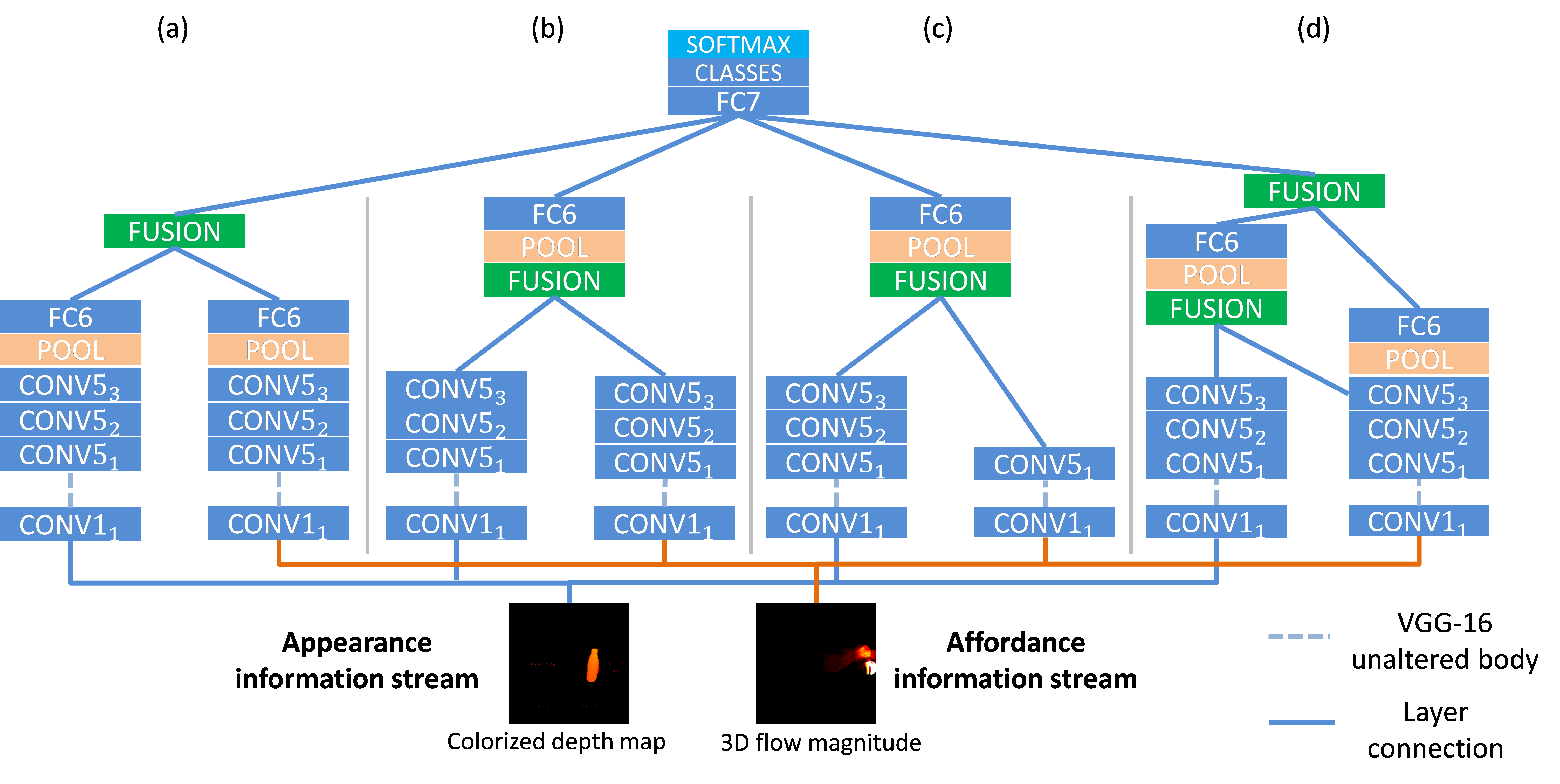
Figure 2. Detailed topology of the GTM architecture for: a) late fusion at FC layer, b) late fusion at last CONV layer, c) slow fusion, and d) multi-level slow fusion. In each case, the left stream represents the appearance and the right the affordance network, respectively.
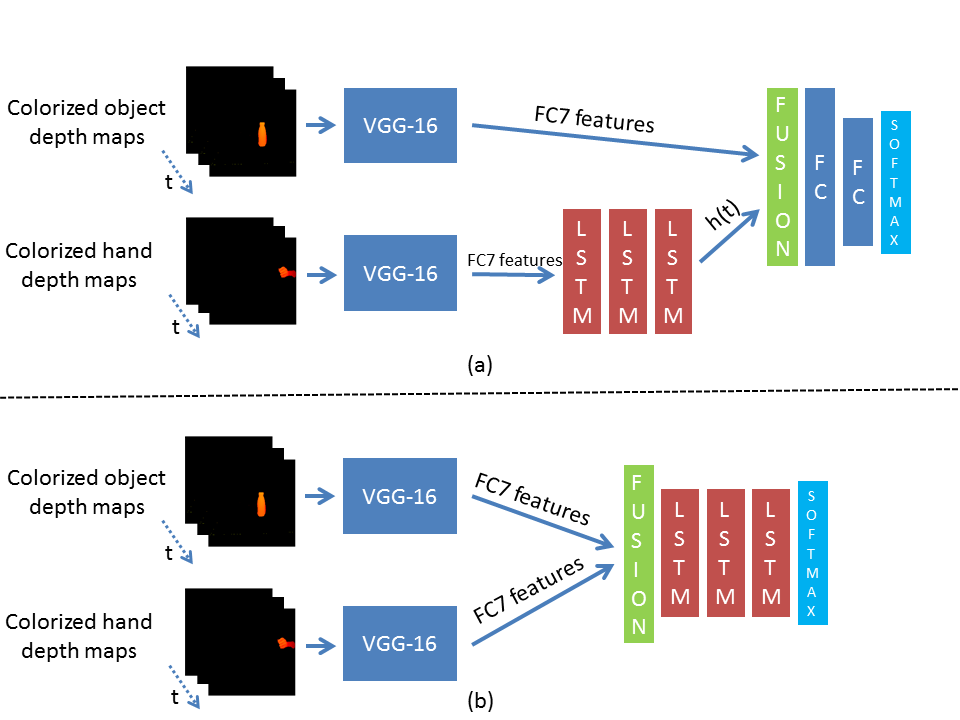
Figure 3. Detailed topology of the GST architecture for: a) late fusion and b) slow fusion.