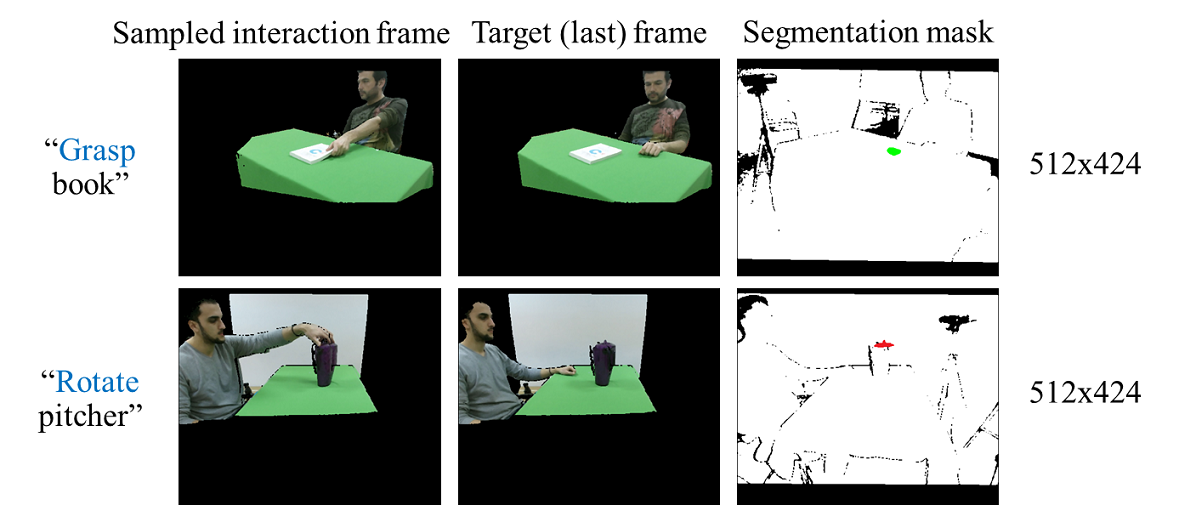
The SOR3D-AFF dataset consists of RGB-D human-object interaction videos. The data are originally captured using Kinect v2 sensors. For each video, the affordance part of the depicted object is annotated at pixel level only in the last (target) frame. The action/affordance label for the entire video is also provided.
Supported affordance types:
- cut
- grasp
- hammer
- lift
- paint
- push
- rotate
- squeeze
- type
Supported objects types:
- ball
- book
- brush
- can
- cup
- hammer
- knife
- pitcher
- smartphone
- sponge
Supported modalities:
- RGB – 1920×1080
- Depthmap – 512×424
- Processed (aligned) RGB – 512×424
Provided annotations:
- Pixel-level affordance labels – last (target) frame only
- Affordance label – sequence only
Original resolution (1920×1080) samples

Processed (512×424) samples
We use the primal-dual framework from this github repo to compute the 3D optical flow between consecutive frames (M. Jaimez et al., “A Primal-Dual Framework for Real-Time Dense RGB-D Scene Flow”, ICRA 2015).
Splits
The dataset consists of 1201 RGB-D videos that are split into 962 videos for training (80%) and 239 videos for validation/test (20%).
| Set | Sessions | Size |
|---|---|---|
| Train | 962 | ~ |
| Val/Test | 239 | ~ |
Usage for Academic Research
SOR3D-AFF is released only for academic research. Any researcher from an educational institute is allowed to use freely for academic purposes only. Redistribution and modification in any way or form are considered illegal. Images in this database are only allowed for demonstration in academic publications and presentations subjected to the Terms and Conditions defined below.
Terms and Conditions of Use
The use of SOR3D is governed by the following terms and conditions:
- Without the expressed permission of VCL, any of the following will be considered illegal: redistribution, modification and commercial usage of the dataset in any way or form, either partially or in its entirety.
- For the sake of privacy, images of all subjects in the dataset are only allowed for demonstration in academic publications and presentations.
- All users of the dataset agree to indemnify, defend and hold harmless, VCL and its officers, employees and agents, individually and collectively, from any and all losses, expenses and damages.
Related Publications
All publications using SOR3D or any parts of it should cite the following publication (pdf, arxiv):
- S. Thermos, P. Daras and G. Potamianos, “A deep learning approach to object affordance segmentation”, IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 2358-2362, Barcelona, Spain, 2020.
By completing and submitting the online form below, you accept all above information, usage restrictions, terms & conditions of use and agree to include the above acknowledgement in any of your publications that will be using the SOR3D or any parts of it.
Acknowledgement
This work has received funding from the EU Horizon 2020 Framework Programme under grant agreement no. 820742 (HR-Recycler project).